通用逼近定理
通用逼近定理(Universal Approximation Theorem)是深度学习和神经网络的数学基础之一。这个定理在理论上证明了神经网络的强大能力,即只要给定足够的神经元和合适的参数,神经网络可以逼近任何连续函数。
定理概述
通用逼近定理的基本思想是,一个前馈神经网络(包含一个隐藏层或多个隐藏层)如果具有足够的神经元,那么它可以以任意精度逼近任何从一个有限维空间到另一个有限维空间的连续函数。这个定理的一个重要应用就是在神经网络中,它解释了为什么神经网络能够处理各种复杂的问题,包括图像识别、语音识别和自然语言处理等。
定理的历史
通用逼近定理的历史可以追溯到1980年代。1989年,George Cybenko首次证明了具有单个隐藏层的前馈神经网络可以逼近任何连续函数。他的证明基于sigmoid激活函数,这是当时神经网络中最常用的激活函数。不久之后,Kurt Hornik在1991年扩展了这个定理,证明了这个定理不仅适用于sigmoid激活函数,而且适用于任何非常数、有界、单调递增的连续函数。
定理的意义
通用逼近定理的重要性在于,它为神经网络的强大能力提供了理论支持。这个定理告诉我们,只要神经网络有足够的神经元和合适的参数,它就可以处理任何复杂的问题。这就解释了为什么神经网络能够在各种任务中表现出色,包括图像识别、语音识别和自然语言处理等。
然而,尽管通用逼近定理证明了神经网络的潜力,但它并没有告诉我们如何找到合适的参数来实现这种逼近。这就是深度学习中训练神经网络的挑战所在。为了找到这些参数,我们需要使用各种优化技术,如梯度下降和反向传播等。
总的来说,通用逼近定理是理解神经网络和深度学习的关键理论基础,它揭示了神经网络的强大能力和潜力。
3.2.4 训练与运行
在前面的讨论中,我们看到,只要能够调节神经网络中各个参数的组合,就能得到想要的任何曲线。可问题是,我们应该如何选取这些参数呢?答案就在于训练。
要想完成神经网络的训练,首先要给这个神经网络定义一个损失函数,用来衡量网络在现有的参数组合下输出的表现。这就类似于第2章中利用线性回归预测房价中的总误差函数(即拟合直线与所有点距离的平方和)L。同样,在单车预测的例子中,我们也可以将损失函数定义为对于所有的数据样本,神经网络预测的单车数量与实际数据中单车数量之差的平方和的均值,即:
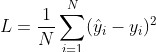
这里,N为样本总量,
有了这个损失函数L,我们就有了调整神经网络参数的方向——尽可能地让L最小化。因此,神经网络要学习的就是神经元之间连边上的权重及偏置,学习的目的是得到一组能够使总误差最小的参数值组合。
这是一个求极值的优化问题,高等数学告诉我们,只需要令导数为零就可以求得。然而,由于神经网络一般非常复杂,包含大量非线性运算,直接用数学求导数的方法行不通,所以,我们一般使用数值的方式来进行求解,也就是梯度下降算法。每次迭代都向梯度的负方向前进,使得误差值逐步减小。参数的更新要用到反向传播算法,将损失函数L沿着网络一层一层地反向传播,来修正每一层的参数。我们在这里不会详细介绍反向传播算法,因为PyTorch已经自动将这个复杂的算法变成了一个简单的命令:backward。只要调用该命令,PyTorch就会自动执行反向传播算法,计算出每一个参数的梯度,我们只需要根据这些梯度更新参数,就可以完成学习。
神经网络的学习和运行通常是交替进行的。也就是说,在每一个周期,神经网络都会进行前馈运算,从输入端运算到输出端;然后,根据输出端的损失值来执行反向传播算法,从而调整神经网络上的各个参数。不停地重复这两个步骤,就可以令神经网络学习得越来越好。
3.2.5 失败的神经预测器
在弄清楚了神经网络的工作原理之后,下面我们来看看如何用神经网络预测共享单车使用量。我们希望仿照预测房价的做法,利用人工神经网络来拟合一个时间段内的单车曲线,并给出在未来时间点单车使用量的曲线。
为了让演示更加简单清晰,我们仅选择了数据中的前50条记录,绘制成如图3.12所示的曲线。在这条曲线中,横坐标是数据记录的编号,纵坐标是对应的单车数量。
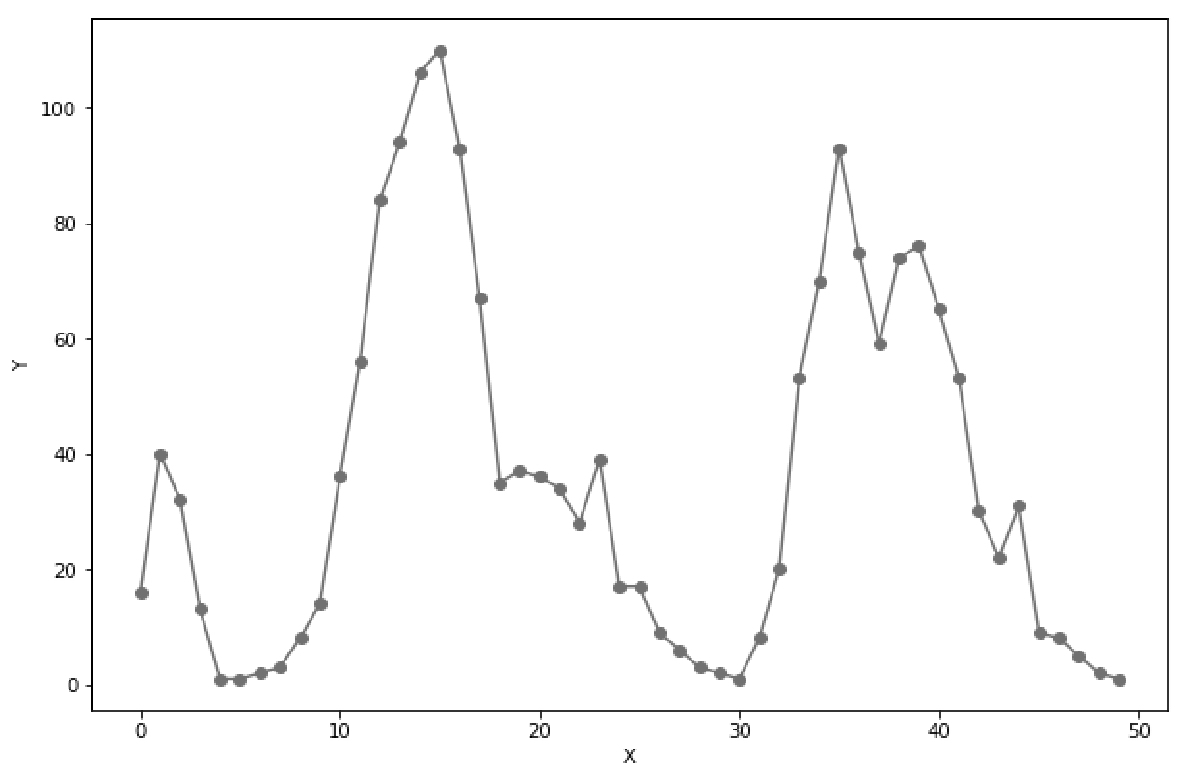
图3.12 部分单车数据曲线
接下来,我们就要设计一个神经网络,它的输入x就是数据编号,输出则是对应的单车数量。通过观察这条曲线,我们发现它至少有3个峰,采用10个隐含单元就足以拟合这条曲线了。因此,我们的人工神经网络架构如图3.13所示。
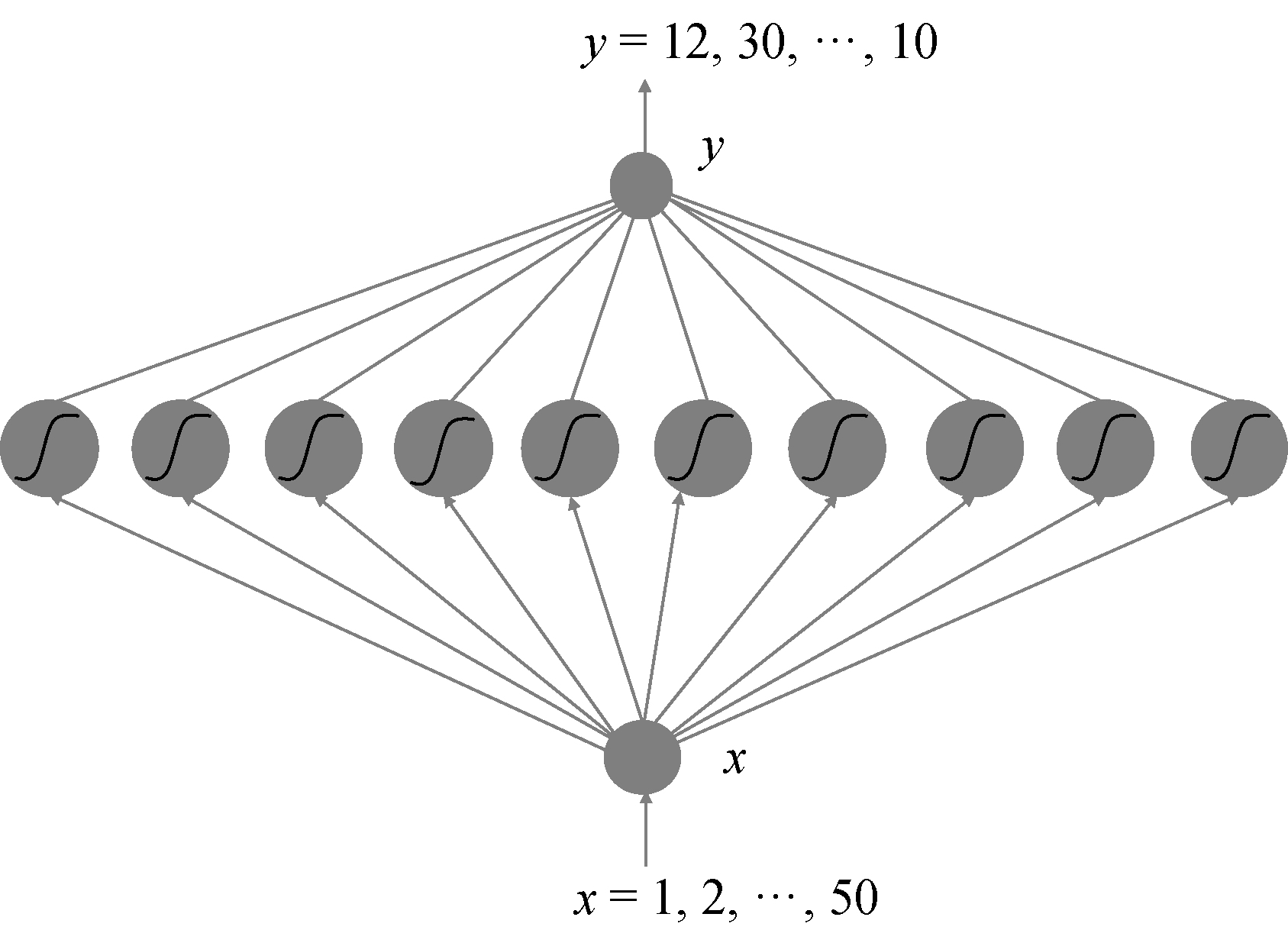
图3.13 人工神经网络架构
接下来,我们动手编写程序实现这个网络。首先导入该程序所使用的所有依赖库。这里我们使用pandas库来读取和操作数据。读者需要先安装这个程序包,在Anaconda环境下运行conda install pandas即可:
import numpy as np
import pandas as pd # 读取CSV文件的库
import torch
import torch.optim as optim
import matplotlib.pyplot as plt
# 直接在Notebook中显示输出图像
%matplotlib inline
接着,从硬盘文件中导入想要的数据。
data_path = 'hour.csv' # 读取数据到内存,rides为一个dataframe对象
rides = pd.read_csv(data_path)
rides.head() # 输出部分数据
counts = rides['cnt'][:50] # 截取数据
x = np.arange(len(counts)) # 获取变量x
y = np.array(counts) # 单车数量为y
plt.figure(figsize = (10, 7)) # 设定绘图窗口大小
plt.plot(x, y, 'o-') # 绘制原始数据
plt.xlabel('X') # 更改坐标轴标注
plt.ylabel('Y') # 更改坐标轴标注
在这里,我们使用了pandas库,从CSV文件中快速导入数据到rides里面。rides可以按照二维表的形式存储数据,并可以像访问数组一样对其进行访问和操作。rides.head()的作用是打印输出部分数据记录。
之后,我们从rides的所有记录中选出前50条,并只筛选出cnt字段放入counts数组中。这个数组就存储了前50条单车使用数量记录。接着,我们绘制前50条记录的图,如图3.13所示。
准备好了数据,我们就可以用PyTorch来搭建人工神经网络了。与第2章的线性回归例子类似,我们首先需要定义一系列的变量,包括所有连边的权重和偏置,并通过这些变量的运算让PyTorch自动生成计算图:
# 输入变量,1,2,3,...这样的一维数组
x = torch.FloatTensor(
np.arange(len(counts),
dtype = float))
# 输出变量,它是从数据counts中读取的每一时刻的单车数,共50个数据点的一维数组,作为标准答案
y = torch.FloatTensor(np.array(counts, dtype = float)))
sz = 10 # 设置隐含神经元的数量
# 初始化输入层到隐含层的权重矩阵,它的尺寸是(1,10)
weights = torch.randn((1, sz), requires_grad = True)
# 初始化隐含层节点的偏置向量,它是尺寸为10的一维向量
biases = torch.randn((sz), requires_grad = True)
# 初始化从隐含层到输出层的权重矩阵,它的尺寸是(10,1)
weights2 = torch.randn((sz, 1), requires_grad = True)
设置好变量和神经网络的初始参数,接下来迭代地训练这个神经网络:
learning_rate = 0.001 # 设置学习率
losses = [] # 该数组记录每一次迭代的损失函数值,以方便后续绘图
x = x.view(50,-1)
y = y.view(50,-1)
for i in range(100000):
# 从输入层到隐含层的计算
hidden = x * weights + biases
# 此时,hidden变量的尺寸是(50,10),即50个数据点,10个隐含神经元
# 将sigmoid函数应用在隐含层的每一个神经元上
hidden = torch.sigmoid(hidden)
# 隐含层输出到输出层,计算得到最终预测值
predictions = hidden.mm(weights2)
# 此时,predictions的尺寸为(50,1),即50个数据点的预测值
# 通过与数据中的标准答案y做比较,计算均方误差
loss = torch.mean((predictions - y) ** 2)
# 此时,loss为一个标量,即一个数
losses.append(loss.data.numpy())
if i % 10000 == 0: # 每隔10000个周期打印一下损失函数数值
print('loss:', loss)
# *****************************************
# 接下来开始执行梯度下降算法,将误差反向传播
loss.backward() # 对损失函数进行梯度反传
# 利用上一步计算中得到的weights、biases等梯度信息更新weights和biases的数值
weights.data.add_(
-learning_rate * weights.grad.data)
biases.data.add_(
-learning_rate * biases.grad.data)
weights2.data.add_(
-learning_rate * weights2.grad.data)
# 清空所有变量的梯度值
weights.grad.data.zero_()
biases.grad.data.zero_()
weights2.grad.data.zero_()
在上面这段代码中,我们进行了100000步训练迭代。在每一次迭代中,我们都将50个数据点的x作为数组全部输入神经网络,并让神经网络按照从输入层到隐含层、再从隐含层到输出层的步骤,一步步完成计算,最终输出对50个数据点的预测数组prediction。
之后,计算prediction和标准答案y之间的误差,并计算出50个数据点的平均误差loss,这就是我们前面提到的损失函数L。接着,调用loss.backward()完成误差沿着神经网络的反向传播过程,从而计算出计算图上每一个叶节点的梯度更新数值,并记录在每个变量的.grad属性中。最后,我们用这个梯度数值来更新每个参数的数值,从而完成了一步迭代。
仔细对比这段代码和第2章中的线性回归代码就会发现,除了中间的运算过程和损失函数有所不同外,其他的操作全部相同。事实上,在本书中,几乎所有的机器学习案例都采用了这样的步骤,即前馈运算、反向传播计算梯度、根据梯度更新参数值。
我们可以打印出Loss随着一步步迭代下降的曲线,这可以帮助我们直观地看到神经网络训练的过程,如图3.14所示。
plt.plot(losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
图3.14 模型的Loss曲线
由该曲线可以看出,随着时间的推移,神经网络预测的误差的确在一步步减小。而且,大约到20000步后,误差基本就不会出现明显的下降了。
接下来,我们可以把训练好的网络对这50个数据点的预测曲线绘制出来,并与标准答案y进行对比,代码如下:
# 获得x包裹的数据
x_data = x.data.numpy()
# 设定绘图窗口大小
plt.figure(figsize = (10, 7))
# 绘制原始数据
xplot, = plt.plot(x_data, y.data.numpy(), 'o')
# 绘制拟合数据
yplot, = plt.plot(x_data, predictions.data.numpy())
# 更改坐标轴标注
plt.xlabel('X')
# 更改坐标轴标注
plt.ylabel('Y')
# 绘制图例
plt.legend([xplot, yplot],['Data', 'Prediction under 1000000 epochs'])
plt.show()
最后的可视化图像如图3.15所示。
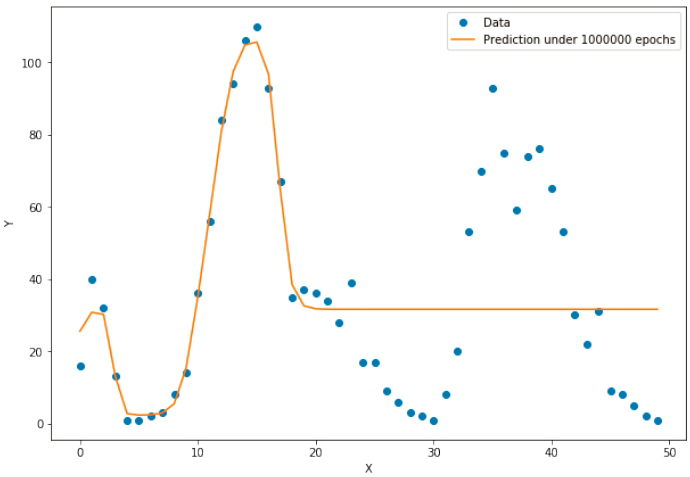
图3.15 模型拟合训练数据的可视化
可以看到,我们的预测曲线在第一个波峰比较好地拟合了数据,但是在此后,它却与真实数据相差甚远。这是为什么呢?
我们知道,x的取值范围是1~50,而所有权重和偏置的初始值都是设定在(-1, 1)的正态分布随机数,那么输入层到隐含层节点的数值范围就成了的-50~50,要想将Sigmoid函数的多个峰值调节到我们期望的位置,需要耗费很多计算时间。事实上,如果让训练时间更长些,我们可以将曲线后面的部分拟合得很好。
这个问题的解决方法是将输入数据的范围做归一化处理,也就是让x的输入数值范围为0~1。因为数据中x的范围是1~50,所以,我们只需要将每一个数值都除以50就可以了:
x = torch.FloatTensor(
np.arange(len(counts),
dtype = float)
/ len(counts))
该操作会使x的取值范围变为0.02, 0.04, …, 1。做了这些改进后再来运行程序,可以看到这次训练速度明显加快,拟合效果也更好了,如图3.16所示。
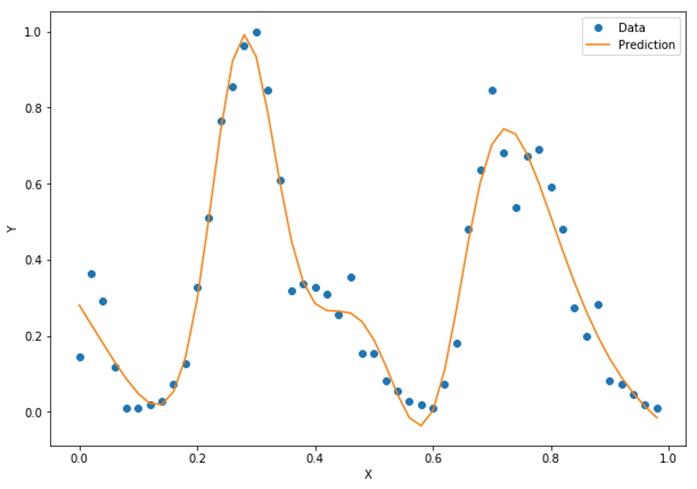
图3.16 改进的模型拟合训练数据的可视化
我们看到,改进后的模型出现了两个波峰,也非常好地拟合了这些数据点,形成一条优美的曲线。
接下来,我们就需要用训练好的模型来做预测了。我们的预测任务是后面50条数据的单车数量。此时x取值是51, 52, …,100,同样也要除以50:
counts_predict = rides['cnt'][50:100] # 读取待预测的后面50个数据点
x = torch.FloatTensor((np.arange(len(counts_predict), dtype = float) + len(counts)) / len(counts))
# 读取后面50个点的y数值,不需要做归一化
y = torch.FloatTensor(np.array(counts_predict, dtype = float))
# 用x预测y
hidden = x.expand(sz, len(x)).t() * weights.expand(len(x), sz) # 从输入层到隐含层的计算
hidden = torch.sigmoid(hidden) # 将sigmoid函数应用在隐含层的每一个神经元上
predictions = hidden.mm(weights2) # 从隐含层输出到输出层,计算得到最终预测值
loss = torch.mean((predictions - y) ** 2) # 计算预测数据上的损失函数
print(loss)
# 将预测曲线绘制出来
x_data = x.data.numpy() # 获得x包裹的数据
plt.figure(figsize = (10, 7)) # 设定绘图窗口大小
xplot, = plt.plot(x_data, y.data.numpy(), 'o') # 绘制原始数据
yplot, = plt.plot(x_data, predictions.data.numpy()) # 绘制拟合数据
plt.xlabel('X') # 更改坐标轴标注
plt.ylabel('Y') # 更改坐标轴标注
plt.legend([xplot, yplot],['Data', 'Prediction']) # 绘制图例
plt.show()
最终,我们得到了如图3.17所示的曲线,直线是我们的模型给出的预测曲线,圆点是实际数据所对应的曲线。模型预测与实际数据竟然完全对不上!
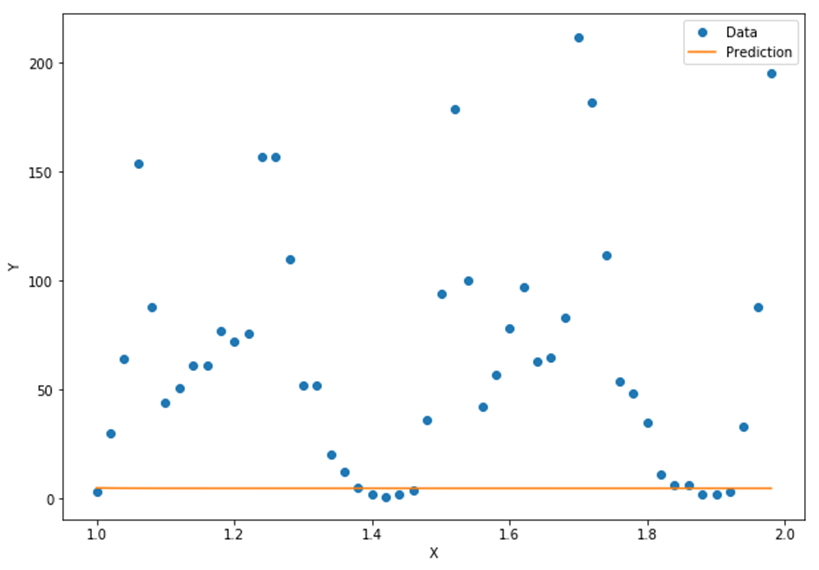
图3.17 模型在测试数据上预测失败的曲线
为什么我们的神经网络可以非常好地拟合已知的50个数据点,却完全不能预测出更多的数据点呢?原因就在于——过拟合。
3.2.6 过拟合
所谓过拟合(overfitting)现象,是指模型可以在训练数据上进行非常好的预测,但在全新的测试数据上表现不佳。在这个例子中,训练数据就是前50个数据点,测试数据就是后面50个数据点。我们的模型可以通过调节参数顺利地拟合训练数据的曲线,但是这种刻意适合完全没有推广价值,导致这条拟合曲线与测试数据的标准答案相差甚远。我们的模型并没有学习到数据中的模式。
这是为什么呢?原因就在于我们选择了错误的特征变量:我们尝试用数据的下标(1, 2, 3, …)或者它的归一化(0.1, 0.2, …)来对y进行预测。然而曲线的波动模式(也就是单车的使用数量)显然并不依赖于下标,而是依赖于诸如天气、风速、星期几和是否是节假日等因素。然而,我们不管三七二十一,硬要用强大的人工神经网络来拟合整条曲线,这自然就导致了过拟合的现象,而且是非常严重的过拟合。
由这个例子可以看出,一味地追求人工智能技术,而不考虑实际问题的背景,很容易让我们走弯路。当我们面对大数据时,数据背后的意义往往可以指导我们更加快速地找到分析大数据的捷径。
在这一节中,我们虽然费了半天劲也没有真正地解决问题,但是仍然学到了不少知识,包括神经网络的工作原理、如何根据问题的复杂度选择隐含层的数量,以及如何调整数据以加速训练。更重要的是,我们从教训中领教了什么叫作过拟合。
本文作者:Maeiee
本文链接:通用逼近定理
版权声明:如无特别声明,本文即为原创文章,版权归 Maeiee 所有,未经允许不得转载!
喜欢我文章的朋友请随缘打赏,鼓励我创作更多更好的作品!
