llama.cpp
大模型推理框架 llama.cpp 是开发者 Georgi Gerganov 基于 Meta 的 LLaMA 模型 手写的纯 C/C++ 版本:
Georgi Gerganov 是资深的开源社区开发者,曾为 OpenAI 的 Whisper 自动语音识别模型开发 whisper.cpp。
特性
- 纯 C/C++ 实现,无依赖
- 支持CPU推理, 当然也支持CUDA/OpenCL推理
- 支持混合 F16 / F32 精度
- 支持 4 位、5 位和 8 位量化
主题
模型支持
- LLaMA
- Alpaca
- GPT4All
- 中文 LLaMA / Alpaca
- Vigogne (法语)
- Vicuna
- Koala
- OpenBuddy (多语言)
- Pygmalion 7B / Metharme 7B
- WizardLM
绑定
- Python: abetlen/llama-cpp-python
- Go: go-skynet/go-llama.cpp
- Node.js: hlhr202/llama-node
- Ruby: yoshoku/llama_cpp.rb
- C#/.NET: SciSharp/LLamaSharp
主题
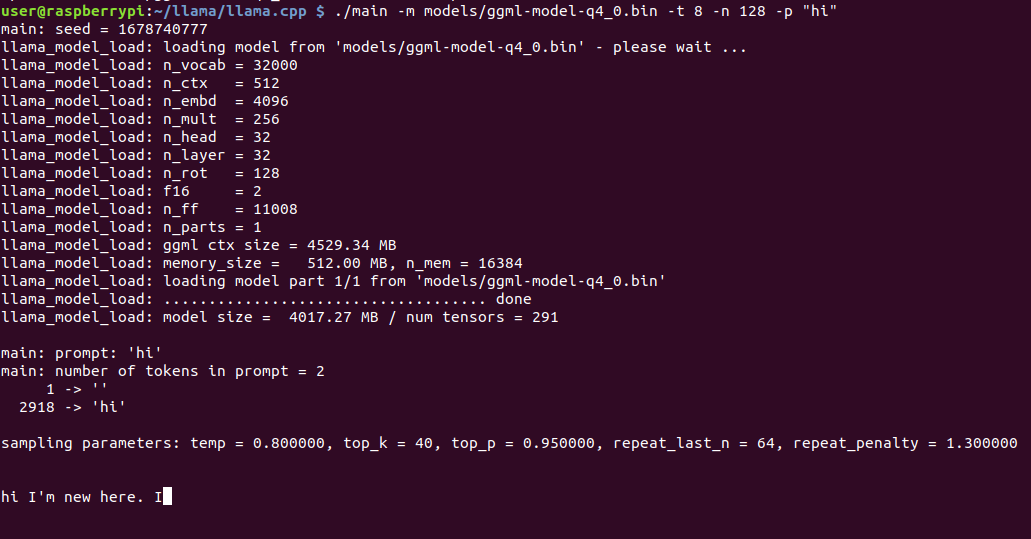
树莓派运行
RPi 4
在 4GB RAM Raspberry Pi 4 成功运行 LLaMA 7B。生成速度很慢 10 sec/token。
Ah, yes. A 3-bit implementation of 7B would fit fully in 4GB of RAM and lead to much greater speeds. This is the same issue as in #97.
3-bit support is a proposed enhancement in GPTQ Quantization (3-bit and 4-bit) #9. GPTQ 3-bit has been shown to have negligible output quality vs uncompressed 16-bit and may even provide better output quality than the current naive 4-bit implementation in llama.cpp while requiring 25% less RAM.
构建失败的配置:
@Ronsor something wrong with your environment.
I UNAME_S: Linux
I UNAME_P: unknown
I UNAME_M: aarch64
能构建成功的配置:
My build log on RPI starts with:
I llama.cpp build info:
I UNAME_S: Linux
I UNAME_P: aarch64
I UNAME_M: aarch64
Raspberry Pi 4 4GB · Issue #58 · ggerganov/llama.cpp (github.com)
Rpi 3
Raspberry Pi 3 Model B Rev 1.2, 1GB RAM + swap (5.7GB on microSD), also works but very slowly
手机运行
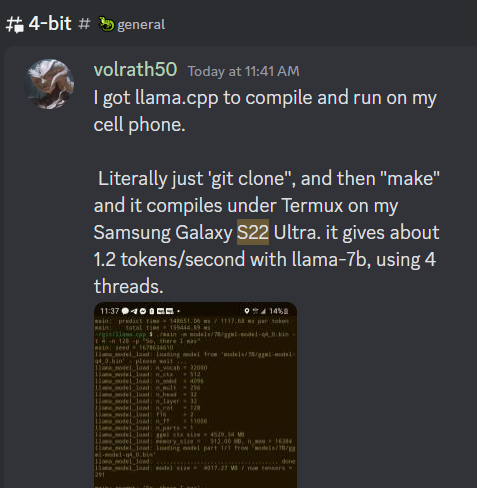
1.2 tokens/s on a Samsung S22 Ultra running 4 threads.
The S22 obviously has a more powerful processor. But I do not think it is 12 times more powerful. It's likely you could get much faster speeds on the Pi.
I'd be willing to bet that the bottleneck is not the processor.
网络资源
【2023-11-25】如何看待llama.cpp?
ggerganov/llama.cpp: Port of Facebook's LLaMA model in C/C++ (github.com)
继续折腾下 llama.cpp + Chinese-LLaMA-Alpaca (listera.top)
本地部署运行中文 LLaMA 模型 - 知乎 (zhihu.com)
本文作者:Maeiee
本文链接:llama.cpp
版权声明:如无特别声明,本文即为原创文章,版权归 Maeiee 所有,未经允许不得转载!
喜欢我文章的朋友请随缘打赏,鼓励我创作更多更好的作品!
