Neural Optical Understanding for Academic Documents
🚀Meta AI 出了一个 OCR 神器:Nougat!🎉
可以轻松将学术 PDF 文档转换为 MultiMarkdown。尤其擅长复杂数学公式。📚➡️🔍
扫描版的 PDF 也能转换!!!基于 Transformer 模型训练而成。🤖📘
一键安装,一键运行,开箱即用!
特性
学术论文转 Markdown(效果亲测):

扫描 PDF 转 Markdown:

扫描畸变 PDF 转 Markdown(来自官网实例):

使用体会
MultiMarkdown
输出格式是 MultiMarkdown,适合于学术文档写作。但我平时在 Obsidian 中使用 Markdown,诸如公式等格式细节,需要手动调整后才能在 Markdown 中正确展示。
公式
能将公式转换成正确的 LaTeX,特别强大!!!学术党喜极而泣有木有!!太幸福了。
表格
能识别表格,但输出的是 LaTeX 格式的表格,在 Markdown 中没法渲染。
图片
生成的文档中不包含图片。图片可以自行从 PDF 中提取。或者手动截图也不失为一个简单办法。
论文
作者:Lukas Blecher, Guillem Cucurull, Thomas Scialom, Robert Stojnic,来自 Meta AI。
Abstract
Scientific knowledge is predominantly stored in books and scientific journals, often in the form of PDFs. However, the PDF format leads to a loss of semantic information, particularly for mathematical expressions. We propose Nougat (Neural Optical Understanding for Academic Documents), a Visual Transformer model that performs an Optical Character Recognition (OCR) task for processing scientific documents into a markup language, and demonstrate the effectiveness of our model on a new dataset of scientific documents. The proposed approach offers a promising solution to enhance the accessibility of scientific knowledge in the digital age, by bridging the gap between human-readable documents and machine-readable text. We release the models and code to accelerate future work on scientific text recognition.
学术知识主要存储在书籍和学术期刊中,通常以PDF形式存在。但PDF格式导致语义信息的丢失,尤其是数学表达式。提出了Nougat(Neural Optical Understanding for Academic Documents),这是一个执行 OCR 任务的视觉变换器模型,用于处理学术文档到标记语言,并在新的学术文档数据集上展示了模型的有效性。
1 Introduction
The majority of scientific knowledge is stored in books or published in scientific journals, most commonly in the Portable Document Format (PDF). Next to HTML, PDFs are the second most prominent data format on the internet, making up 2.4% of common crawl [1]. However, the information stored in these files is very difficult to extract into any other formats. This is especially true for highly specialized documents, such as scientific research papers, where the semantic information of mathematical expressions is lost.
Existing Optical Character Recognition (OCR) engines, such as Tesseract OCR [2], excel at detecting and classifying individual characters and words in an image, but fail to understand the relationship between them due to their line-by-line approach. This means that they treat superscripts and subscripts in the same way as the surrounding text, which is a significant drawback for mathematical expressions. In mathematical notations like fractions, exponents, and matrices, relative positions of characters are crucial.
现有的光学字符识别(OCR)引擎,如Tesseract OCR [2],擅长在图像中检测和分类单个字符和单词,但由于其逐行的方法,无法理解它们之间的关系。这意味着它们将上标和下标与周围的文本一视同仁,这对于数学表达式是一个重大的缺陷。在分数、指数和矩阵等数学符号中,字符的相对位置至关重要。
Converting academic research papers into machine-readable text also enables accessibility and searchability of science as a whole. The information of millions of academic papers can not be fully accessed because they are locked behind an unreadable format. Existing corpora, such as the S2ORC dataset [3], capture the text of 12M [2] papers using GROBID [4], but are missing meaningful representations of the mathematical equations.
对 [2] 的注释:The paper reports 8.1M papers but the authors recently updated the numbers on the GitHub page https://github.com/allenai/s2orc
To this end, we introduce Nougat, a Transformer based model that can convert images of document pages to formatted markup text.
The primary contributions in this paper are
-
Release of a pre-trained model capable of converting a PDF to a lightweight markup language. We release the code and the model on GitHub: https://github.com/facebookresearch/nougat
-
We introduce a pipeline to create dataset for pairing PDFs to source code
-
Our method is only dependent on the image of a page, allowing access to scanned papers and books
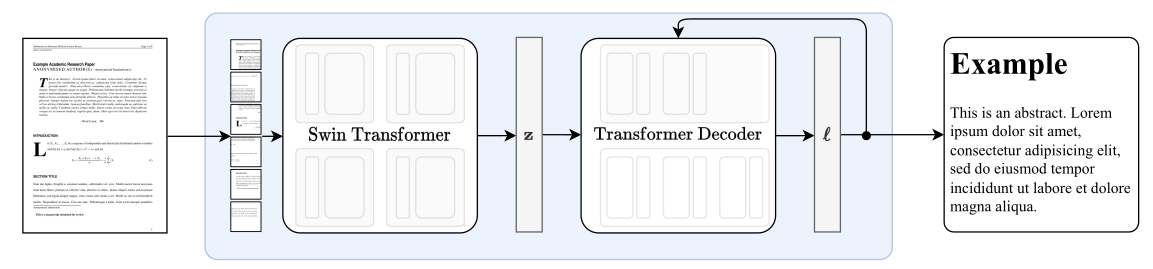
Figure 1: Our simple end-to-end architecture followin Donut [28]. The Swin Transformer encoder takes a document image and converts it into latent embeddings, which are subsequently converted to a sequence of tokens in a autoregressive manner
图1:我们的简单端到端架构遵循Donut [28]。Swin Transformer 编码器接受一个文档图像并将其转换为潜在嵌入,随后以自回归的方式将其转换为一系列的令牌。
2 Related Work
Optical Character Recognition (OCR) is an extensively researched field in computer vision for a variety applications, such as document digitalization [2, 5], handwriting recognition and scene text recognition [6, 7, 8].
More concretely, recognizing mathematical expressions is a heavily researched subtopic. Grammar based methods [9, 10, 11] for handwritten mathematical expressions were improved upon by different encoder-decoder models. The fully convolutional model [12] was succeeded by various RNN decoder models [13, 14, 15, 16, 17], both for handwritten and printed formulas. Recently, the decoder [18, 19] as well as the encoder [20] were replaced with the Transformer [21] architecture.
Visual Document Understanding (VDU) is another related topic of deep learning research and focuses on extracting relevant information of a variety of document types. Previous works depend on pre-trained models that learn to extract information by jointly modeling text and layout information using the Transformer architecture. The LayoutLM model family [22, 23, 24] uses masked layout prediction task to capture the spatial relationships between different document elements.
Open source solutions with a related goal as ours include GROBID [4], which parses digital-born scientific documents to XML with a focus on the bibliographic data and pdf2htmlEX [25], that converts digital-born PDFs to HTML while preserving the layout and appearance of the document. However, both solutions can not recover the semantic information of mathematical expressions.
3 Model
Previous VDU methods either rely on OCR text from a third party tool [22, 23, 26] or focus on document types such as recepits, invoices or form-like documents [27]. Recent studies [28, 29] show that an external OCR engine is not necessarily needed to achieve competitive results in VDU.
The architecture is a encoder-decoder transformer [21] architecture, that allows for an end-to-end training procedure. We build on the Donut [28] architecture. The model does not require any OCR related inputs or modules. The text is recognized implicitly by the network. See Fig. 1 for an overview of the approach.
Encoder The visual encoder receives a document image
Decoder The encoded image
Following Kim et al. [28], we use the implementation of the mBART [32] decoder. We use the same tokenizer as Taylor et al. [33] because their model is also specialized in the scientific text domain.
3.1 Setup
We render the document images at a resolution of 96 DPI. Due to the restrictive possible input dimensions of the Swin Transformer we choose the input size
The Transformer decoder has a maximal sequence length of
We also test experiment with a smaller model (250M parameters) with a slightly smaller sequence length of (S=3584) and only 4 decoder layers, where we start from the pre-trained base model.
During inference the text is generated using greedy decoding.
Training We use an AdamW optimizer [34] to train for 3 epochs with an effective batch size of 192. Due to training instabilities, we choose a learning rate of
3.2 Data Augmentation 数据增强
In image recognition tasks, it is often beneficial to use data augmentation to improve generalization. Since we are only using digital-born academic research papers, we need to employ a number of transformations to simulate the imperfections and variability of scanned documents. These transformations include erosion, dilation, gaussian noise, gaussian blur, bitmap conversion, image compression, grid distortion and elastic transform [35]. Each has a fixed probability of being applied to a given image. The transformations are implemented in the Albumentations[36] library. For an overview of the effect of each transformation, see Fig. 2.
在图像识别任务中,使用数据增强通常有助于提高泛化能力。由于我们仅使用数字出生的学术研究论文,因此我们需要采用多种变换来模拟扫描文档的不完善性和可变性。这些转换包括侵蚀、膨胀、高斯噪声、高斯模糊、位图转换、图像压缩、网格扭曲和弹性变换[35]。每种变换都有一个固定的概率被应用于给定的图像。这些转换在 Albumentations[36]库中实现。要查看每种变换的效果概述,请参见图2。

Figure 2: List of the different image augmentation methods used during training on an example snippet form a sample document.
图2:在样本文档的一个示例片段上进行训练时使用的不同图像增强方法的列表。
During training time, we also add perturbations to the ground truth text by randomly replacing tokens. We found this to reduce the collapse into a repeating loop significantly. For more details, see Section 5.4.
4 Datasets
To the best of our knowledge there is no paired dataset of PDF pages and corresponding source code out there, so we created our own from the open access articles on arXiv.4 For layout diversity we also include a subset of the PubMed Central 5 (PMC) open access non-commercial dataset. During the pretraining, a portion of the Industry Documents Library 6 (IDL) is included. See Table A.1 for the dataset composition.
Footnote 4: https://arxiv.org/
Footnote 5: https://www.ncbi.nlm.nih.gov/pmc/
Footnote 6: https://www.industrydocuments.ucsf.edu/
arXiv We collected the source code and compiled PDFs from 1,748,201 articles released on arXiv. To ensure consistent formatting, we first process the source files using LaTeXML 7 and convert them into HTML5 files. This step was important as it standardized and removed ambiguity from the LaTeX source code, especially in mathematical expressions. The conversion process included replacing user-defined macros, standardizing whitespace, adding optional brackets, normalizing tables, and replacing references and citations with their correct numbers.
Footnote 7: http://dlmf.nist.gov/LaTeXML/
We then parse the HTML files and convert them into a lightweight markup language that supports various elements such as headings, bold and italic text, algorithms, LaTeX inline and display math and LaTeX tables. This way, we ensure that the source code is properly formatted and ready for further processing.
The process is visualized in Fig. 3.
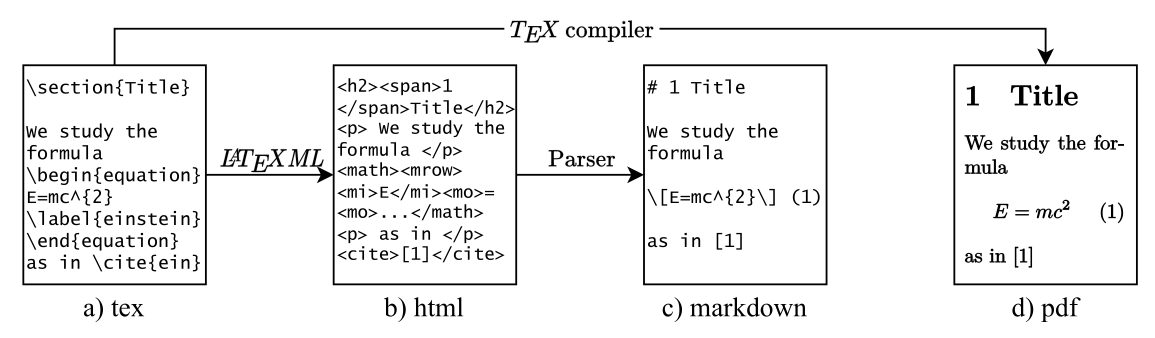
Figure 3: Data processing. The source file is converted into HTML which is then converted to Markdown. a) The LaTeX source provided by the authors. b) The HTML file computed form the LaTeX source using LaTeXML. c) The Markdown file parsed from the HTML file. d) The PDF file provided by the authors
PMC We also processed articles from PMC, where XML files with semantic information are available in addition to the PDF file. We parse these files into the same markup language format as the arXiv articles. We chose to use far fewer articles from PMC because the XML files are not always as rich in semantic information. Often times equations and tables are stored as images and these cases are not trivial to detect, which leads to our decision to limit the use of PMC articles to the pre-training phase.
PMC 我们还处理了来自PMC的文章,在PDF文件之外,还提供带有语义信息的XML文件。我们将这些文件解析为与arXiv文章相同的标记语言格式。我们选择使用更少的PMC文章,因为XML文件在语义信息上并不总是那么丰富。很多时候,方程式和表格都被存储为图像,这些情况不容易检测,这导致了我们决定仅在预训练阶段使用PMC文章。
The XML files are parsed into the same markup language as described above.
IDL The IDL is a collection of documents produced by industries that have an impact on public health and is maintained by the University of California, San Francisco Library. Biten et al. [37] provide high quality OCR text for PDFs from the IDL dataset. This does not include text formatting and is only used for pre-training to teach the model basic OCR of scanned documents.
4.1 Splitting the pages
We split the markdown files according to the page breaks in the PDF file and rasterize each page as an image to create the final paired dataset. During the compilation, the LaTeX compiler determines the page breaks of the PDF file automatically. Since we are not recompiling the LaTeX sources for each paper, we must heuristically split the source file into parts, which correspond to different pages. To achieve that we are using the embedded text on the PDF page and match it to source text.
However, figures and tables in the PDF may not correspond to their position in the source code. To address this issue, we remove these elements in a pre-processing step using pdffigures2 [38]. The recognized captions are are then compared to the captions in the XML file and matched based on their Levenshtein distance [39]. Once the source document has been split into individual pages, the removed figures and tables are reinserted at the end of each page.
For a better matching we also replaced unicode characters in the PDF text with corresponding LaTeX commands using the pylatexenc-library 8.
Footnote 8: https://github.com/phfaist/pylatexenc
Bag of Words matching First we extract the text lines from the PDF using MuPDF 9 and preprocess them to remove page numbers and potential headers/footers. We then use a Bag of Words model [40] with TF-IDF vectorizer and a linear Support Vector Machine classifier. The model is fitted to the PDF lines with the page number as label. Next we split the LaTeX source into paragraphs and predict the page number for each of them.
Footnote 9: https://mupdf.com/
Ideally, the predictions will form a stair case function but in practice the signal will be noisy. To find the best boundary points we employ a similar logic as decision trees and minimize a measure based on the Gini impurity
where
The best splitting position
The search process starts with all paragraphs and for each subsequent page break, the lower bound of the search interval is set to the previous split position. See Fig. 4 for a visualization of an example page.
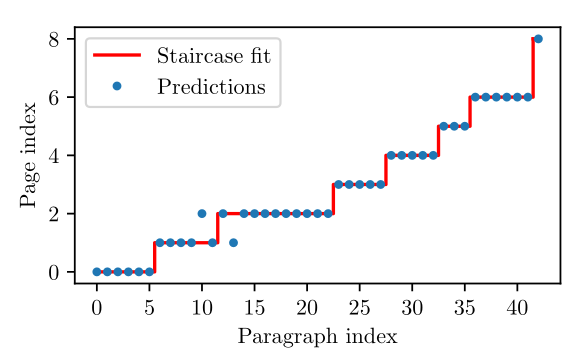
Figure 4: Example for splitting the paragraphs in the source code into different pages. The points in blue denote the page index predicted by the SVM.
Fuzzy matching After this first coarse document splitting we try to find the exact position within the paragraph. This is done by comparing the source text within the neighborhood of the predicted splitting position to the last sentences of the previous page of the embedded PDF text, and the first sentences of the next page using the fuzzysearch library10. If the two dividing points are at the same location in the source text, the page break is considered "accurate" and receives a score of 1. On the other hand, if the splitting positions differ, the one with the smallest normalized Levenshtein distance is selected and given a score of 1 minus the distance. To be included in the dataset, a PDF page must have an average score of at least 0.9 for both page breaks. This results in an acceptance rate of about
Footnote 10: https://github.com/taleinat/fuzzysearch
4.2 Ground truth artifacts
Because the dataset was pre-processed by LaTeXML, the markup version of the source code can contain artifacts and commands from unsupported packages. The HTML file may contain subsection titles with numbering even though they are not numbered in the PDF. There may also be instances where figures or tables are missing from the ground truth due to processing errors.
In addition, the splitting algorithm of the source code will in some cases include text from the previous page or cut off words from the end. This is especially true for "invisible" characters used for formatting, like italic, bold text or section header.
For PMC papers the inline math is written as Unicode or italic text, while display math equations or tables are often included in image format and will therefore be ignored.
Each of these issues reduces the overall data quality. However, the large number of training samples compensates for these small errors.
## 5 Results & Evaluation
In this section we discuss the results and performance of the model. For an example see Fig. 5 or go to Sec. B. The model focuses only on the important content relevant features of the page. The box around the equations is skipped.
在本节中,我们讨论模型的结果和性能。有关示例,请参见图5或转到B节。该模型只关注页面的重要内容相关特征。方程式周围的框被跳过。

Figure 5: Example of a page with many mathematical equations taken from [41]. Left: Image of a page in the document, Right: Model output converted to LaTeX and rendered to back into a PDF. Examples of scanned documents can be found in the appendix B.
5.1 Metrics
We report the following metrics on our test set.
Edit distance The edit distance, or Levenshtein distance [39], measures the number of character manipulations (insertions, deletions, substitutions) it takes to get from one string to another. In this work we consider the normalized edit distance, where we divide by the total number of characters.
BLEU The BLEU [42] metric was originally introduced for measuring the quality of text that has been machine-translated from one language to another. The metric computes a score based on the number of matching n-grams between the candidate and reference sentence.
METEOR Another machine-translating metric with a focus on recall instead of precision, introduced in [43].
F-measure We also compute the F1-score and report the precision and recall.
5.2 Text modalities
In a scientific research article, there are three distinct types of text: 1) plain text, which comprises the majority of the document, 2) mathematical expressions, and 3) tables. It is important to separately examine each of these components during the evaluation process. This is necessary because in LaTeX, there are multiple ways to express the same mathematical expression. While some variability has been eliminated during the LaTeXML pre-processing step, there still is a significant amount of ambiguity present, like ordering of subscript and superscript, equivalent commands with different notation (stackrel, atop, substack or frac, over), situationally interchangeable commands (bm, mathbf, boldsymbol, bf or left(, big(, etc.), whitespace commands, additional layers of brackets, and more. As a consequence, there can be a discrepancy between prediction and ground truth, even if the rendered formulas appear identical.
In addition, it is not always possible to determine, where a inline math environment ends and text begins, when writing numbers and punctuation Example: $\mathrm{H}_{0}$1, vs. H$_{0}1, $ \rightarrow) H({}_{0})1, vs. H({}_{0})1,. This ambiguity reduces both math and plain text scores.
The expected score for mathematical expressions is lower than for plain text.
5.3 Comparison
We present our results in Table 1. As expected, the mathematical expressions have the worst agreement with the ground truth. For the plain text, most discrepancies come from formatting ambiguities and missing text due to inline math, as described above. The output format of GROBID is an XML file, which we convert into a compatible markup language, similar to the PMC or arXiv files. To some extent, GROBID provides support for formulas in its output, but it identifies and stores them as the Unicode representations embedded in the PDF. We replace each Unicode symbol with its corresponding LaTeX command to increase the similarity. Additionally, GROBID mislabels small inline expressions as text. For identified formulas, GROBID stores the bounding box coordinates. We modify the program by sending the snippet to the external formula recognition software LaTeX-OCR [20]. This way we can also get a signal for math modality. The reported results in this section are quite poor, primarily due to the amount of missed formulas by GROBID and the equation prediction accuracy is affected by the quality of the bounding boxes. The performance of the embedded PDF text alone is better than GROBID, which is due to formatting differences for the title page or reference section.
我们在表1中展示了我们的研究结果。如所预期,数学表达式与实际数据的一致性是最差的。对于普通文本,大多数的差异来自于格式的歧义和因内嵌数学公式而导致的文本缺失,如上所述。GROBID的输出格式是XML文件,我们将其转化为与PMC或arXiv文件类似的标记语言。在一定程度上,GROBID在其输出中支持公式,但它将它们识别并存储为PDF中嵌入的Unicode表示形式。我们将每个Unicode符号替换为其对应的LaTeX命令,以增加其相似度。此外,GROBID会将小的内嵌表达式误标为文本。对于已识别的公式,GROBID会存储其边界框坐标。我们修改了该程序,将代码片段发送到外部的公式识别软件LaTeX-OCR [20]。这样我们也可以为数学模态获得一个信号。本节报告的结果相当不理想,这主要是因为GROBID错过了很多公式,而且方程式的预测准确性受到边界框质量的影响。单独使用PDF内嵌文本的性能比GROBID好,这是由于标题页或参考部分的格式差异所导致的。
Both Nougat small and base are able to outperform the other approach and achieve high scores in all metrics. We note that the performance of the smaller model is on par with the larger base model.
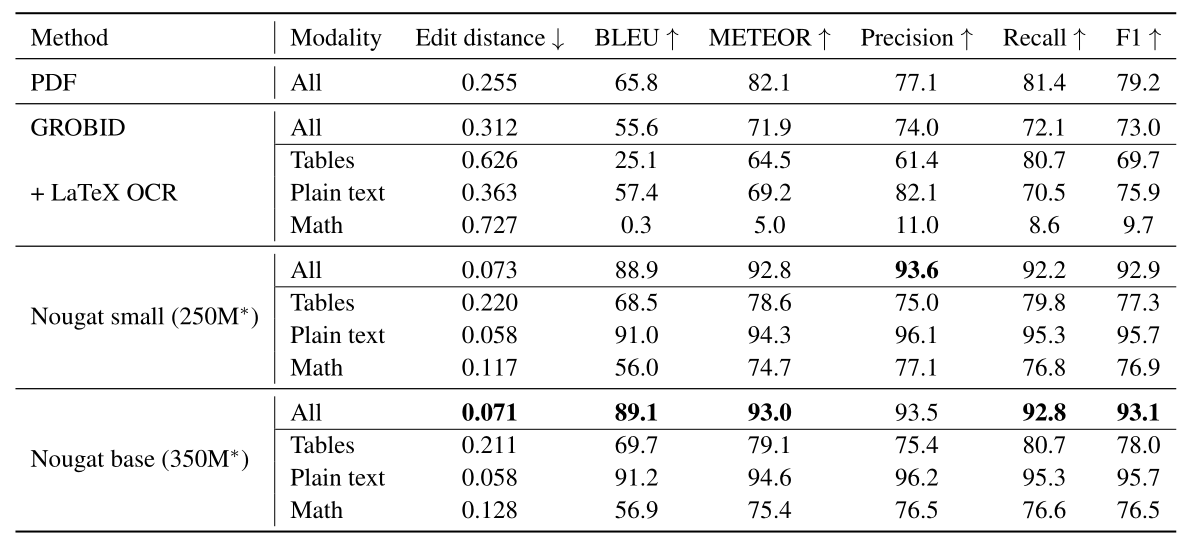
Table 1: Results on arXiv test set. PDF is the text embedded in the PDF file. The modality “All” refers to the output text without any splitting. *Number of parameters.
5.4 Repetitions during inference
We notice that the model degenerates into repeating the same sentence over and over again. The model can not recover from this state by itself. In its simplest form, the last sentence or paragraph is repeated over and over again. We observed this behavior in
It can also happen that the model alternates between two sentences but sometimes changes some words, so a strict repetition detection will not suffice. Even harder to detect are predictions where the model counts its own repetitions, which sometimes happens in the references section.
In general we notice this kind behavior after a mistake by the model. The model is not able to recover from the collapse.
Anti-repetition augmentation Because of that we introduce a random perturbation during training. This helps the model to learn how to handle a wrongly predicted token. For each training example, there is a fixed probability that a random token will be replaced by any other randomly chosen token. This process continues until the newly sampled number is greater than a specified threshold (in this case, 10%). We did not observe a decrease in performance with this approach, but we did notice a significant reduction in repetitions. Particularly for out-of-domain documents, where we saw a 32% decline in failed page conversions.
Repetition detection Since we are generating a maximum of (4096) tokens the model will stop at some point, however it is very inefficient and resource intensive to wait for a "end of sentence" token, when none will come. To detect the repetition during inference time we look at the largest logit value
Here
If this signal drops below a certain threshold (we choose 6.75) and stays below for the remainder of the sequence, we classify the sequence to have repetitions.
During inference time, it is obviously not possible to compute the to the end of the sequence if our goal is to stop generation at an earlier point in time. So here we work with a subset of the last 200 tokens and a half the threshold. After the generation is finished, the procedure as described above is repeated for the full sequence.
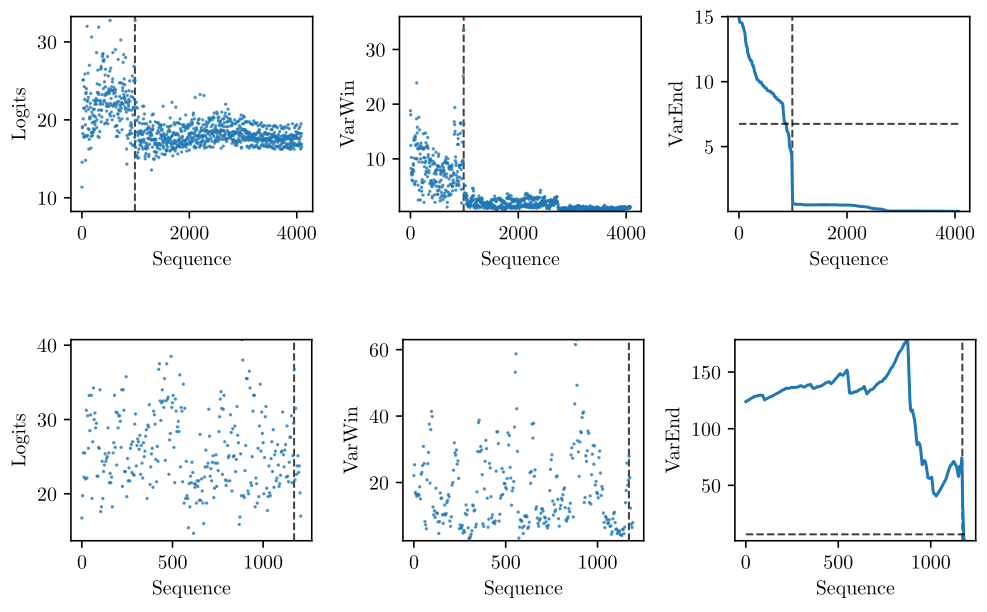
Figure 6: Examples for repetition detection on logits. Top: Sample with repetition, Bottom: Sample without repetition. Left: Highest logit score for each token in the sequence
5.5 Limitations & Future work
Utility The utility of the model is limited by a number of factors. First, the problem with repetitions outlined in section 5.4. The model is trained on research papers, which means it works particularly well on documents with a similar structure. However, it can still accurately convert other types of documents.
Nearly every dataset sample is in English. Initial tests on a small sample suggest that the model's performance with other Latin-based languages is satisfactory, although any special characters from these languages will be replaced with the closest equivalent from the Latin alphabet. Non-Latin script languages result in instant repetitions.
几乎每一个数据集样本都是英文的。初步在小样本上的测试表明,该模型在处理其他基于拉丁文的语言时的表现是令人满意的,尽管这些语言的任何特殊字符都将被替换为拉丁字母中最接近的等效字符。对于非拉丁文书写的语言,会导致即时的重复。
Generation Speed On a machine with a NVIDIA A10G graphics card with 24GB VRAM we can process 6 pages in parallel. The generation speed depends heavily on the amount of text on any given page. With an average number of tokens of
Future work The model is trained on one page at a time without knowledge about other pages in the document. This results in inconsistencies across the document. Most notably in the bibliography where the model was trained on different styles or section titles where sometimes numbers are skipped or hallucinated. Though handling each page separately significantly improves parallelization and scalability, it may diminish the quality of the merged document text.
The primary challenge to solve is the tendency for the model to collapse into a repeating loop, which is left for future work.
6 Conclusion
In this work, we present Nougat, an end-to-end trainable encoder-decoder transformer based model for converting document pages to markup. We apply recent advances in visual document understanding to a novel OCR task. Distinct from related approaches, our method does not rely on OCR or embedded text representations, instead relying solely on the rasterized document page. Moreover, we have illustrated an automatic and unsupervised dataset generation process that we used to successfully train the model for scientific document to markup conversion. Overall, our approach has shown great potential for not only extracting text from digital-born PDFs but also for converting scanned papers and textbooks. We hope this work can be a starting point for future research in related domains.
All the code for model evaluation, training and dataset generation can be accessed at https://github.com/facebookresearch/nougat.
7 Acknowledgments
Thanks to Ross Taylor, Marcin Kardas, Iliyan Zarov, Kevin Stone, Jian Xiang Kuan, Andrew Poulton and Hugo Touvron for their valuable discussions and feedback.
Thanks to Faisal Azhar for the support throughout the project.
References
-
Sebastian Spiegler. Statistics of the Common Crawl Corpus 2012, June 2013. URL https://docs.google.com/file/d/1_9698uglerxB9nAglvaHkEgU-iZNm1TvVGCuW7245-WGvZq47teNpb_uL5N9.
-
Smith [2007] R. Smith. An Overview of the Tesseract OCR Engine. In Ninth International Conference on Document Analysis and Recognition (ICDAR 2007) Vol 2, pages 629-633, Curitiba, Parana, Brazil, September 2007. IEEE. ISBN 978-0-7695-2822-9. doi: 10.1109/ICDAR.2007.4376991. URL http://ieeexplore.ieee.org/document/4376991/ISSN: 1520-5363.
-
Lo et al. [2020] Kyle Lo, Lucy Lu Wang, Mark Neumann, Rodney Kinney, and Daniel Weld. S2ORC: The Semantic Scholar Open Research Corpus. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4969-4983, Online, July 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.447. URL https://aclanthology.org/2020.acl-main.447.
-
Lopez [2023] Patrice Lopez. GROBID, February 2023. URL https://github.com/kermitt2/grobid. original-date: 2012-09-13T15:48:54Z.
-
Moysset et al. [2017] Bastien Moysset, Christopher Kermorvant, and Christian Wolf. Full-Page Text Recognition: Learning Where to Start and When to Stop, April 2017. URL http://arxiv.org/abs/1704.08628. arXiv:1704.08628 [cs].
-
Bautista and Atienza [2022] Darwin Bautista and Rowei Atienza. Scene Text Recognition with Permuted Autoregressive Sequence Models, July 2022. URL http://arxiv.org/abs/2207.06966. arXiv:2207.06966 [cs] version: 1.
-
Li et al. [2022] Minghao Li, Tengchao Lv, Jingye Chen, Lei Cui, Yijuan Lu, Dinei Florencio, Cha Zhang, Zhoujun Li, and Furu Wei. TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models, September 2022. URL http://arxiv.org/abs/2109.10282. arXiv:2109.10282 [cs].
-
Diaz et al. [2021] Daniel Hernandez Diaz, Siyang Qin, Reeve Ingle, Yasuhisa Fujii, and Alessandro Bissacco. Rethinking Text Line Recognition Models, April 2021. URL http://arxiv.org/abs/2104.07787. arXiv:2104.07787 [cs].
-
MacLean and Labahn [2013] Scott MacLean and George Labahn. A new approach for recognizing handwritten mathematics using relational grammars and fuzzy sets. International Journal on Document Analysis and Recognition (IJDAR), 16(2):139-163, June 2013. ISSN 1433-2825. doi: 10.1007/s10032-012-0184-x. URL https://doi.org/10.1007/s10032-012-0184-x.
-
Awal et al. [2014] Ahmad-Montaser Aval, Harold Mouchre, and Christian Viard-Gaudin. A global learning approach for an online handwritten mathematical expression recognition system. Pattern Recognition Letters, 35(C):68-77, January 2014. ISSN 0167-8655.
-
Alvaro et al. [2014] Francisco Alvaro, Joan-Andreu Sanchez, and Jose-Miguel Benedi. Recognition of on-line handwritten mathematical expression using 2D stochastic context-free grammars and hidden Markov models. Pattern Recognition Letters, 35:58-67, January 2014. ISSN 0167-8655. doi: 10.1016/j.patrec.2012.09.023. URL https://www.sciencedirect.com/science/article/pii/S016786551200308X.
-
Yan et al. [2020] Zuoyu Yan, Xiaode Zhang, Liangcai Gao, Ke Yuan, and Zhi Tang. ConvMath: A Convolutional Sequence Network for Mathematical Expression Recognition, December 2020. URL http://arxiv.org/abs/2012.12619. arXiv:2012.12619 [cs].
-
Deng et al. [2016] Yuntian Deng, Anssi Kanervisto, Jeffrey Ling, and Alexander M. Rush. Image-to-Markup Generation with Coarse-to-Fine Attention, September 2016. URL http://arxiv.org/abs/1609.04938. arXiv:1609.04938 [cs] version: 1.
-
Le and Nakagawa [2017] Anh Duc Le and Masaki Nakagawa. Training an End-to-End System for Handwritten Mathematical Expression Recognition by Generated Patterns. In 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), volume 01, pages 1056-1061, November 2017. doi: 10.1109/ICDAR.2017.175. ISSN: 2379-2140.
-
Singh [2018] Sumeet S. Singh. Teaching Machines to Code: Neural Markup Generation with Visual Attention, June 2018. URL http://arxiv.org/abs/1802.05415. arXiv:1802.05415 [cs].
-
Zhang et al. [2018] Jianshu Zhang, Jun Du, and Lirong Dai. Multi-Scale Attention with Dense Encoder for Handwritten Mathematical Expression Recognition, January 2018. URL http://arxiv.org/abs/1801.03530. arXiv:1801.03530 [cs].
-
Wang and Liu [2019] Zelun Wang and Jyh-Charn Liu. Translating Math Formula Images to LaTeX Sequences Using Deep Neural Networks with Sequence-level Training, September 2019. URL http://arxiv.org/abs/1908.11415. arXiv:1908.11415 [cs, stat].
-
Zhao et al. [2021] Wenqi Zhao, Liangcai Gao, Zuoyu Yan, Shuai Peng, Lin Du, and Ziyin Zhang. Handwritten Mathematical Expression Recognition with Bidirectionally Trained Transformer, May 2021. URL http://arxiv.org/abs/2105.02412. arXiv:2105.02412 [cs].
-
Mahdavi et al. [2019] Mahshad Mahdavi, Richard Zanibbi, Harold Mouchere, Christian Viard-Gaudin, and Utpal Garain. ICDAR 2019 CROHME + TFD: Competition on Recognition of Handwritten Mathematical Expressions and Typeset Formula Detection. In 2019 International Conference on Document Analysis and Recognition (ICDAR), pages 1533-1538, Sydney, Australia, September 2019. IEEE. ISBN 978-1-72813-014-9. doi: 10.1109/ICDAR.2019.00247. URL https://ieeexplore.ieee.org/document/8978036/.
-
LaTeX OCR, February 2023. URL https://github.com/lukas-blecher/LaTeX-OCR. original-date: 2020-12-11T16:35:13Z.
-
[21] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention Is All You Need, December 2017. URL http://arxiv.org/abs/1706.03762. arXiv:1706.03762 [cs].
-
[22] Yiheng Xu, Minghao Li, Lei Cui, Shaohan Huang, Furu Wei, and Ming Zhou. LayoutLM: Pre-training of Text and Layout for Document Image Understanding. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1192-1200, August 2020. doi: 10.1145/3394486.3403172. URL http://arxiv.org/abs/1912.13318 [cs].
-
[23] Yang Xu, Yiheng Xu, Tengchao Lv, Lei Cui, Furu Wei, Guoxin Wang, Yijuan Lu, Dinei Florencio, Cha Zhang, Wanxiang Che, Min Zhang, and Lidong Zhou. LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding, January 2022. URL http://arxiv.org/abs/2012.14740. arXiv:2012.14740 [cs].
-
[24] Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, and Furu Wei. LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking, July 2022. URL http://arxiv.org/abs/2204.08387. arXiv:2204.08387 [cs].
-
[25] Lu Wang and Wanmin Liu. Online publishing via pdf2htmlEX, 2013. URL https://www.tug.org/TUGb boat/tb34-3/tb108wang.pdf.
-
[26] Srikar Appalaraju, Bhavan Jasani, Bhargava Urala Kota, Yusheng Xie, and R. Manmatha. DocFormer: End-to-End Transformer for Document Understanding, September 2021. URL http://arxiv.org/abs/2106.11539. arXiv:2106.11539 [cs].
-
[27] Bodhisattwa Prasad Majumder, Navneet Potti, Sandeep Tata, James Bradley Wendt, Qi Zhao, and Marc Najork. Representation Learning for Information Extraction from Form-like Documents. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 6495-6504, Online, July 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.580. URL https://aclanthology.org/2020.acl-main.580.
-
[28] Geewook Kim, Teakgyu Hong, Moonbin Yim, Jeongyeon Nam, Jinyoung Park, Jinyeong Yim, Wonseok Hwang, Sangdoo Yun, Dongyoon Han, and Seunghyun Park. OCR-free Document Understanding Transformer, October 2022. URL http://arxiv.org/abs/2111.15664. arXiv:2111.15664 [cs].
-
[29] Brian Davis, Bryan Morse, Bryan Price, Chris Tensmeyer, Curtis Wigington, and Vlad Morariu. End-to-end Document Recognition and Understanding with Dessurt, June 2022. URL http://arxiv.org/abs/2203.16618. arXiv:2203.16618 [cs].
-
[30] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, and Baining Guo. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, August 2021. URL http://arxiv.org/abs/2103.14030. arXiv:2103.14030 [cs].
-
[31] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, June 2021. URL http://arxiv.org/abs/2010.11929. arXiv:2010.11929 [cs].
-
[32] Mike Lewis, Yinhan Liu, Naman Goyal, Marjan Ghazvininejad, Abdelrahman Mohamed, Omer Levy, Ves Stoyanov, and Luke Zettlemoyer. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension, October 2019. URL http://arxiv.org/abs/1910.13461. arXiv:1910.13461 [cs, stat].
-
[33] Ross Taylor, Marcin Kardas, Guillem Cucurull, Thomas Scialom, Anthony Hartshorn, Elvis Saravia, Andrew Poulton, Viktor Kerkez, and Robert Stojnic. Galactica: A Large Language Model for Science, November 2022. URL http://arxiv.org/abs/2211.09085. arXiv:2211.09085 [cs, stat].
-
[34] Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization, January 2019. URL http://arxiv.org/abs/1711.05101. arXiv:1711.05101 [cs, math] version: 3.
-
[35] P.Y. Simard, D. Steinkraus, and J.C. Platt. Best practices for convolutional neural networks applied to visual document analysis. In Seventh International Conference on Document Analysis and Recognition, 2003. Proceedings., volume 1, pages 958-963, Edinburgh, UK, 2003. IEEE Comput. Soc. ISBN 978-0-7695-1960-9. doi: 10.1109/ICDAR.2003.1227801. URL http://ieeexplore.ieee.org/document/1227801/.
-
[36] Alexander Buslaev, Vladimir I. Iglovikov, Eugene Khvedchenya, Alex Parinov, Mikhail Druzhinin, and Alexandr A. Kalinin. Albumentations: Fast and Flexible Image Augmentations. Information, 11(2):125, February 2020. ISSN 2078-2489. doi: 10.3390/info11020125. URL https://www.mdpi.com/2078-2489/11/2/125.
-
[37] Ali Furkan Biten, Ruben Tito, Lluis Gomez, Ernest Valveny, and Dimosthenis Karatzas. OCR-IDL: OCR Annotations for Industry Document Library Dataset, February 2022. URL http://arxiv.org/abs/2202.12985. arXiv:2202.12985 [cs].
-
[38] Christopher Clark and Santosh Divvala. PDFFigures 2.0: Mining Figures from Research Papers. In Proceedings of the 16th ACM/IEEE-CS on Joint Conference on Digital Libraries, pages 143-152, Newark New Jersey USA, June 2016. ACM. ISBN 978-1-4503-4229-2. doi: 10.1145/2910896.2910904. URL https://dl.acm.org/doi/10.1145/2910896.2910904.
-
[39] V. Levenshtein. Binary codes capable of correcting deletions, insertions, and reversals. Soviet physics. Doklady, 1965. URL https://www.semanticscholar.org/paper/Binary-codes-capable-of-correcting-deletions%2C-and-Levenshtein/b2f8876482c97e804bb50a5e2433881ae31d0cdd.
-
[40] Zellig S. Harris. Distributional Structure. WORD, 10(2-3):146-162, 1954. doi: 10.1080/00437956.1954.11659520. URL https://doi.org/10.1080/00437956.1954.11659520. Publisher: Routledge _eprint: https://doi.org/10.1080/00437956.1954.11659520.
-
[41] Ben Sorscher, Robert Geirhos, Shashank Shekhar, Surya Ganguli, and Ari S. Morcos. Beyond neural scaling laws: beating power law scaling via data pruning, November 2022. URL http://arxiv.org/abs/2206.14486. arXiv:2206.14486 [cs, stat].
-
[42] Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. Bleu: a Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pages 311-318, Philadelphia, Pennsylvania, USA, July 2002. Association for Computational Linguistics. doi: 10.3115/1073083.1073135. URL https://aclanthology.org/P02-1040.
-
[43] Satanjeev Banerjee and Alon Lavie. METEOR: An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. In Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization, pages 65-72, Ann Arbor, Michigan, June 2005. Association for Computational Linguistics. URL https://aclanthology.org/W05-0909.
-
[44] Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The Curious Case of Neural Text Degeneration, February 2020. URL http://arxiv.org/abs/1904.09751. arXiv:1904.09751 [cs].
-
[45] Herman W. (Herman William) March and Henry C. (Henry Charles) Wolff. Calculus. New York : McGraw-Hill, 1917. URL http://archive.org/details/calculus00marciala.
-
[46] Kinetics and Thermodynamics in High-Temperature Gases, January 1970. URL https://ntrs.nasa.gov/citations/19700022795. NTRS Report/Paten Number: N70-32106-116 NTRS Document ID: 19700022795 NTRS Research Center: Glenn Research Center (GRC).
-
[47] Angela Fan, Mike Lewis, and Yann Dauphin. Hierarchical Neural Story Generation. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 889-898, Melbourne, Australia, July 2018. Association for Computational Linguistics. doi: 10.18653/v1/P18-1082. URL https://aclanthology.org/P18-1082.
-
[48] Meet Shah, Xinlei Chen, Marcus Rohrbach, and Devi Parikh. Cycle-Consistency for Robust Visual Question Answering, February 2019. URL http://arxiv.org/abs/1902.05660. arXiv:1902.05660 [cs].
输出
输出格式为 .mmd 文件。.mmd 文件格式是 MultiMarkdown 的扩展名,这是一个轻量级标记语言。MultiMarkdown 是 Markdown 语言的扩展,增加了对表格、脚注、参考文献等的支持。在提到的上下文中,.mmd 文件主要与 Mathpix Markdown 兼容,并使用了 LaTeX 表格。它特别适用于需要包含数学和科学内容的文档格式化。
网络资源
- X 上的 Lukas Blecher:“🎉New Paper🎉 Nougat - Neural Optical Understanding for Academic Documents 📄💻 It can extract text, equations and tables from academic PDFs with high precision. See examples here: https://t.co/yk1yzulr5G Paper: https://t.co/ksQhaoo2DN Code and models: https://t.co/22oRjKPPPV” / X
- [2308.13418] Nougat: Neural Optical Understanding for Academic Documents
- Nougat
- facebookresearch/nougat: Implementation of Nougat Neural Optical Understanding for Academic Documents
本文作者:Maeiee
本文链接:Neural Optical Understanding for Academic Documents
版权声明:如无特别声明,本文即为原创文章,版权归 Maeiee 所有,未经允许不得转载!
喜欢我文章的朋友请随缘打赏,鼓励我创作更多更好的作品!
