seq2seq
时序数据(文本、音视频)无处不在。许多场景下,需要将一种时序数据转换为另一种,如机器翻译、语音识别。
seq2seq 是解决这一问题的模型,又称为 Encoder-Decoder 模型,由 Encoder(处理输入数据)和 Decoder(处理输出数据)构成。谷歌翻译2016年底,开始在生产中使用该模型。
以神经机器翻译为例:输入“你好”,经过 seq2seq 模型,输出“Hello”。
编码器-解码器结构
seq2seq 由由 Encoder 和 Decoder构成,整体结构为:
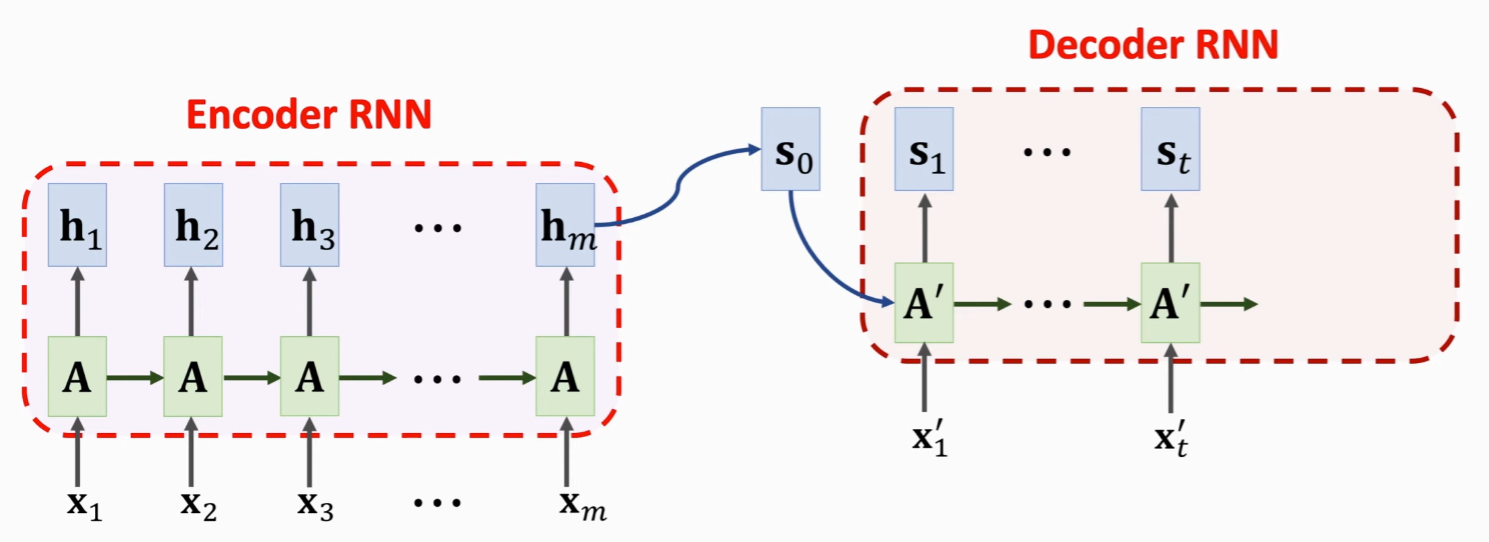
来源:YouTube - Shusen Wang
具体过程:
- 编码器首先逐个处理输入序列中的每个元素
- 输入序列全输入编码器后,编码形成上下文向量(Context Vector)
- 将上下文向量传入解码器
- 解码器逐个生成输出序列元素
在机器翻译场景下:上下文是一个向量,编码器和解码器通常都是循环神经网络(RNN)。
编码器结构
编码器通常是一个循环神经网络(RNN),如长短期记忆网络(LSTM)或门控循环单元(GRU)。
输入序列元素,按照先后顺序,每次处理一个元素。被处理元素,首先经过 Embedding 编码为向量,之后传入 RNN,RNN 将生成一个隐藏状态。在下一时刻,下一个元素与该隐藏状态一同输入 RNN,得到新的隐藏状态,依次类推。
待整个序列输入完成后,最终的隐藏状态(Hidden State),就是要传给解码器的。
graph LR
E1[Embedding] -->|input| L1[LSTM]
E2[Embedding] -->|input| L2[LSTM]
E3[Embedding] -->|input| L3[LSTM]
E4[Embedding] -->|input| L4[LSTM]
E5[Embedding] -->|input| L5[LSTM]
L1 -->|h1| L2
L2 -->|h2| L3
L3 -->|h3| L4
L4 -->|h4| L5
L5 --> H[h]
subgraph Japanese
J1[吾輩] --> E1
J2[は] --> E2
J3[猫] --> E3
J4[で] --> E4
J5[ある] --> E5
end解码器结构
解码器也是一个RNN。它使用编码器的最后一个隐藏状态(Hidden State)来初始化其自身的隐藏状态,然后开始生成输出序列。
在每个时间步,解码器都会生成一个新的输出元素,并更新其隐藏状态。到解码器生成一个特殊的结束符号,或者达到预设的最大序列长度。
graph LR
H((h)) -->|initial state| D1[LSTM]
D1 --> D2[LSTM] --> D3[LSTM] --> D4[LSTM] --> D5[LSTM]
D1 -->|output| W1[单词1]
D2 -->|output| W2[单词2]
D3 -->|output| W3[单词3]
D4 -->|output| W4[单词4]
D5 -->|output| W5[单词5]训练Seq2Seq模型
Seq2Seq 模型通常使用监督学习进行训练。
- 训练集:输入序列和对应的目标输出序列对
- 首先将输入序列传递给编码器,然后将编码器的最后一个隐藏状态用作解码器的初始隐藏状态。
- 然后,将目标输出序列(除去最后一个元素)传递给解码器作为其输入,并要求它预测目标输出序列的下一个元素
- 我们使用一个适当的损失函数(如交叉熵损失)来度量解码器的预测与真实目标之间的差距
- 并使用反向传播和优化器来更新模型的参数。
注意力机制
虽然 Seq2Seq 模型在许多任务中表现出色,但它有一个主要的限制,即必须依赖编码器的最后一个隐藏状态来捕获输入序列的所有信息。对于长序列,这可能是一个挑战。RNN 一次只能处理一个单词,串行无法并行化。
为了解决这个问题,研究人员引入了注意力机制。Transformer 不需要一次处理一个单词,这使得它比RNNs能更好地并行化,从而减少训练时间。
注意力机制允许解码器在生成每个输出元素时“查看”输入序列的所有元素,而不仅仅是编码器的最后一个隐藏状态。具体来说,它计算一个权重分布,对输入序列中的每个元素赋予一个权重,然后将输入序列的加权和作为一个“上下文向量”传递给解码器。这个上下文向量提供了关于输入序列的丰富信息,帮助解码器生成更准确的输出。
参考资料
本文作者:Maeiee
本文链接:seq2seq
版权声明:如无特别声明,本文即为原创文章,版权归 Maeiee 所有,未经允许不得转载!
喜欢我文章的朋友请随缘打赏,鼓励我创作更多更好的作品!
